

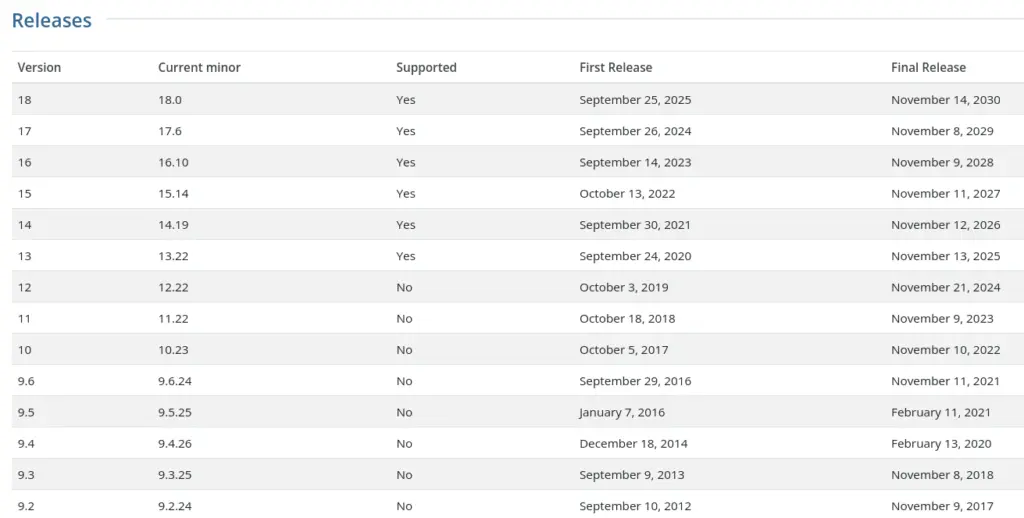
2025 წლის 25 სექტემბერს გამოვიდა DBMS PostgreSQL 18-ის სტაბილური ვერსია. ახალი ფილიალისთვის განახლებები გამოვა ხუთი წლის განმავლობაში, 2030 წლის ნოემბრამდე. PostgreSQL 18-ის გამოშვებისთვის მზადება პროექტის წლიური განვითარების ციკლის ფარგლებში მიმდინარეობდა. PostgreSQL 13.x-ის, ყველაზე ძველი მხარდაჭერილი ფილიალის მხარდაჭერა შეწყდება 2025 წლის 13 ნოემბერს.
PostgreSQL 18-ში შეტანილი ძირითადი ცვლილებები და დამატებებია:
- დაემატა ასინქრონული შეყვანა/გამოტანის ქვესისტემა, რაც ზრდის შეყვანა/გამოტანის გამტარუნარიანობას და აცილებს დაყოვნებებს. ყველა პლატფორმაზე ხელმისაწვდომი AIO-ის უნივერსალური განხორციელების გარდა (io_method=worker), რომელიც დაფუძნებულია რამდენიმე დამმუშავებელი პროცესის შესრულებაზე (ნაგულისხმევად 3), Linux-ში შეიძლება გამოყენებულ იქნას ასინქრონული შეყვანა/გამოტანის ინტერფეისი io_uring (io_method=io_uring), რომელიც მხარდაჭერილია Linux-ის ბირთვის 5.1 ვერსიიდან მოყოლებული. ასინქრონული შეყვანა/გამოტანა ჯერჯერობით მხოლოდ ზოგიერთი ოპერაციის დასაჩქარებლად გამოიყენება, რომლებიც დაკავშირებულია მონაცემთა ფაილური სისტემიდან წაკითხვასთან, როგორიცაა თანმიმდევრული მიმოხილვა, ინდექსების ბიტური რუკის სკანირება და გაწმენდა (vacuum). ზოგიერთ ტესტში AIO-ის გამოყენება იწვევს მწარმოებლურობის 2-3-ჯერ ზრდას. ჩაწერის ოპერაციები კვლავ სინქრონულ რეჟიმში სრულდება ACID-ის მოთხოვნების დასაკმაყოფილებლად;
- განხორციელდა „skip scan“ ოპტიმიზაცია მრავალსვეტიან ინდექსებში, რის წყალობითაც ინდექსი შეიძლება გამოყენებულ იქნას არა მხოლოდ პირველი ინდექსირებული სვეტის და სვეტების სრული კომბინაციის შესამოწმებლად, არამედ დანარჩენი ინდექსირებული სვეტების ცალკე დასამუშავებლად. მაგალითად, ადრე, B-tree ინდექსის შექმნისას სვეტებზე „(status, date)“, ინდექსი გამოიყენებოდა მხოლოდ იმ მოთხოვნებისთვის, რომლებიც ამოწმებდნენ „status“ ველს ან ორივე ველს „status“ და „date“, ხოლო მოთხოვნაში მხოლოდ „date“ ველის შემოწმებისას ხდებოდა ცხრილის შიგთავსის სკანირება. რეჟიმი „skip scan“ საშუალებას იძლევა გარკვეულ სიტუაციებში ინდექსის სკანირება მოხდეს მხოლოდ „date“ ველის მოთხოვნისას. ეს რეჟიმი გამოიყენება მხოლოდ „B-tree“ ინდექსებისთვის, როდესაც მოთხოვნაში გამოიყენება პირობითი ოპერატორი „=“ ინდექსირებულ ველზე, იმ სიტუაციებში, როდესაც გამოტოვებულ ველს აქვს განსხვავებული მნიშვნელობების მცირე რაოდენობა (მაგალითად, ოპტიმიზაცია იმუშავებს, თუ „status“ ველს აქვს რამდენიმე ფიქსირებული მნიშვნელობა);
- დაემატა ოპტიმიზაციები, რომლებიც უფრო ეფექტურად იყენებენ ინდექსებს მოთხოვნებისთვის, რომლებიც შეიცავენ „OR“ და „IN (…)“ კონსტრუქციებს „WHERE“ ბლოკში, ასევე ზრდიან ცხრილების გაერთიანების დაგეგმვისა და შესრულების მწარმოებლურობას (მაგალითად, დაჩქარებულია ჰეშების შერწყმის კოდი და ნებადართულია ინკრემენტალური დახარისხების გამოყენება ცხრილების შერწყმისას);
- დაემატა GIN ინდექსების (Generalized Inverted Index) აგების პარალელიზაციის მხარდაჭერა, რომლებიც გამოიყენება კომპოზიტური მნიშვნელობების, მაგალითად, მასივების ინდექსირებისთვის, და სრულტექსტური მონაცემების ან JSON სტრუქტურების მოსაძიებლად;
- დაემატა მატერიალიზებული ხედების და გასაღებების შექმნის შესაძლებლობა B-tree სტრუქტურის გარეშე, „unique“ ნიშნის მქონე ინდექსებით ცხრილების სექციონირებისთვის;
- გაიზარდა ბლოკირების საერთო მწარმოებლურობა მოთხოვნებისთვის, რომლებიც მუშაობენ დიდი რაოდენობით ცხრილებთან, ასევე გაუმჯობესდა სექციონირებული ცხრილების მიმართ მოთხოვნების დამუშავება, რაც აჩქარებს გამოუყენებელი სექციების გაფილტვრას და შერწყმის (JOIN) ოპერაციებს;
- დაჩქარდა ტექსტური ოპერაციები, როგორიცაა ზედა/ქვედა რეგისტრში გადაყვანის ფუნქციები. დაემატა PG_UNICODE_FAST რეჟიმი Unicode სიმბოლოების ლოკალის თვისებების აღრიცხვის დასაჩქარებლად;
- განხორციელდა მოთხოვნათა დამგეგმავის სტატისტიკის შენახვის შესაძლებლობა PostgreSQL-ის მნიშვნელოვან რელიზებს შორის განახლების შემდეგ. ეს ცვლილება საშუალებას იძლევა თავიდან იქნას აცილებული რესურსმომხმარებელი ოპერაცია „ANALYZE“ ახალი ვერსიის გაშვების შემდეგ, რომლის დასრულებამდე შეინიშნება DBMS-ის მწარმოებლურობის შემცირება;
- გაიზარდა pg_upgrade უტილიტის მწარმოებლურობა, რომელიც გამოიყენება PostgreSQL-ის ახალ მნიშვნელოვან გამოშვებაზე ავტომატურად გადასვლისთვის. ოპტიმიზაციები განსაკუთრებით შესამჩნევია მონაცემთა ბაზების განახლებისას, რომლებიც შეიცავს დიდი რაოდენობით ობიექტებს, როგორიცაა ცხრილები და თანმიმდევრობები. pg_upgrade-ის მუშაობის დასაჩქარებლად ასევე დაემატა დროშა ‑jobs N შემოწმებების N ნაკადში პარალელიზაციისთვის და დროშა „‑swap“ მონაცემთა კატალოგების სრულად შესაცვლელად ბმულების დადგენის, კლონირების და ფაილების კოპირების გარეშე;
- დაემატა ვირტუალური გენერირებადი სვეტების მხარდაჭერა, რომელთა მნიშვნელობა გამოითვლება მოთხოვნების შესრულებისას, დისკზე შენახვის გარეშე. თუ „CREATE TABLE…“ გამოსახულებაში გენერირებადი სვეტებისთვის მითითებულია მხოლოდ საკვანძო სიტყვა „GENERATED“ ტიპის (STORED ან VIRTUAL) დაკონკრეტების გარეშე, მაშინ ნაგულისხმევად გამოიყენება ახალი ვარიანტი ძველი განხორციელების ნაცვლად. ძველ განხორციელებაში მნიშვნელობები გენერირდებოდა „INSERT“ ან „UPDATE“ ოპერაციების შესრულებისას და ინახებოდა დისკზე შემდგომი გამოყენებისთვის. ვირტუალური გენერირებადი სვეტების ნაკლოვანებაა მათი ინდექსებში გამოყენების შეუძლებლობა, ხოლო უპირატესობა — მონაცემების ნორმალიზაციისა და ცვლილებების შესრულების შესაძლებლობა რეალურ დროში (აქტუალურია JSON მონაცემებთან მუშაობისას). რაც შეეხება კლასიკურ შენახულ გენერირებად სვეტებს, ახალ გამოშვებაში მათთვის უზრუნველყოფილია ლოგიკური რეპლიკაციის მხარდაჭერა;
- INSERT, UPDATE, DELETE და MERGE ბრძანებებში განხორციელდა წარსული (OLD) და მიმდინარე (CURRENT) მნიშვნელობების გამოტანის შესაძლებლობა RETURNING გამოსახულებაში. მაგალითად, „UPDATE… RETURNING WITH (OLD AS o, NEW AS n) o., n..“;
- დაემატა ფუნქცია uuidv7() შემთხვევითი უნიკალური იდენტიფიკატორების UUIDv7 ფორმატში გენერირებისთვის. UUID-ის გენერირებისთვის ძველი ფუნქციისგან (gen_random_uuid), რომელიც ახლა ასევე ხელმისაწვდომია uuidv4() სახელწოდებით, განსხვავებით, UUIDv7-ში შემთხვევითი მნიშვნელობის გარდა შედის გენერირების დროც. UUID-ის მნიშვნელობაში დალაგებული ნაწილების არსებობა (პირველი 12 სიმბოლო — ეპოქალური დრო, ხოლო შემდეგი 18 — შემთხვევითი მნიშვნელობა) ზრდის დახარისხებისა და ინდექსირების ეფექტურობას, რაც აქტუალურია, რადგან UUID-ები ჩვეულებრივ გამოიყენება პირველადი გასაღებებისთვის (მაგალითად, ახლო დროში შექმნილი გასაღებები ინდექსში ერთმანეთის გვერდით განთავსდება);
- „LIKE“ ოპერაციაში განხორციელდა ტექსტთან შედარებების მხარდაჭერა, რომლებშიც გამოიყენება „collation“ ლოკალის არადეტერმინირებული თვისებები, რაც საშუალებას იძლევა შედარებები შესრულდეს სიმბოლოების მნიშვნელობის გათვალისწინებით (მაგალითად, შედარებისას შესაძლოა არ იქნას გათვალისწინებული მახვილი). დაემატა ფუნქცია CASEFOLD სიმბოლოების რეგისტრის შესაცვლელად „collation“ ლოკალის თვისებების გათვალისწინებით (მაგალითად, ზოგიერთ სიმბოლოს აქვს ორზე მეტი პატარა ასოების ვარიანტი ან შედარებისას საჭიროებს დიდ რეგისტრში გადაყვანას და არა პატარაში);
- დაემატა დროებითი შეზღუდვების (temporal constraint) გამოყენების შესაძლებლობა. „PRIMARY KEY“ და „UNIQUE“ მნიშვნელობებში დროებითი შეზღუდვების დასამატებლად უნდა გამოიყენოთ გამოსახულება „WITHOUT OVERLAPS“, ხოლო „FOREIGN KEY“ მნიშვნელობაში — გამოსახულება PERIOD. მაგალითად, პირველადი გასაღებების განსაზღვრისას შესაძლებელია გასაღებების შეზღუდვა გადაფარვითი დროის ინტერვალებით;
- დაემატა ბრძანება „CREATE FOREIGN TABLE… LIKE command“ გარე ცხრილის სქემის შესაქმნელად ლოკალური ცხრილის განსაზღვრების საფუძველზე;
- დაემატა DBMS-თან დაკავშირების მხარდაჭერა OAUTH 2.0-ზე დაფუძნებული ავთენტიფიკაციის გამოყენებით, პაროლის ნაცვლად წვდომის ტოკენით. OAUTH-ის გამოყენება საშუალებას იძლევა არ შეინახოთ პაროლები DB-ში, არამედ მომხმარებლების იდენტიფიცირება მოხდეს გარე სერვისების საშუალებით, ასევე გამოიყენოთ ისეთი შესაძლებლობები, როგორიცაა ორფაქტორიანი ავთენტიფიკაცია და ერთჯერადი შესვლა (SSO);
- დაემატა ფუნქცია ssl_tls13_ciphers(), რომლის მეშვეობითაც შესაძლებელია დაშიფვრის ალგორითმების სიის განსაზღვრა, რომლებიც დასაშვებია TLSv1.3 პროტოკოლის გამოყენებით დაკავშირებისას;
- მოძველებულ და წასაშლელად დაგეგმილთა სიაში გადავიდა md5 ალგორითმის გამოყენებით პაროლების ჰეშირების ავთენტიფიკაციის მხარდაჭერა. md5-ის ნაცვლად რეკომენდებულია SCRAM ალგორითმის (SCRAM‑SHA-256) გამოყენება, რომელიც გამოჩნდა PostgreSQL 10-ში. დამატებით აღინიშნება SCRAM-ზე დაფუძნებული ავთენტიფიკაციის გადამისამართების მხარდაჭერის განხორციელება postgres_fdw-სა და dblink-ის საშუალებით გარე PostgreSQL სერვერებთან დაკავშირებისას;
- „EXPLAIN ANALYZE“ ოპერაციის შესრულებისას უზრუნველყოფილია ინფორმაციის გამოტანა ინდექსებში ძიების ოპერაციების რაოდენობის შესახებ ინდექსის სკანირებისას და ბუფერებზე მიმართვების რაოდენობის შესახებ მოთხოვნის შესრულებისას. „EXPLAIN ANALYZE VERBOSE“ გამოტანაში შედის სტატისტიკა CPU-ის, WAL-ჟურნალის და წაკითხვის ოპერაციების ინტენსივობის შესახებ. ცხრილში pg_stat_all_tables დაემატა ინფორმაცია VACUUM ოპერაციაზე და ცხრილების ანალიზზე დახარჯული დროის შესახებ. მოწოდებულია სტატისტიკა შეყვანა/გამოტანის ინტენსივობისა და WAL-ჟურნალზე დატვირთვის შესახებ ცალკეული კავშირების მიხედვით. pg_stat_subscription_stats-სა და ლოგებში დაემატა ინფორმაცია კონფლიქტების დიაგნოსტიკის შესახებ ჩაწერის ოპერაციების შესრულებისას ლოგიკური რეპლიკაციის დროს;
- ახალ ინსტალაციებში ნაგულისხმევად ჩართულია საკონტროლო ჯამების გამოყენება შენახული მონაცემების მთლიანობის შესამოწმებლად. ამ ქცევის გასაუქმებლად initdb-ის გაშვებისას უნდა მიუთითოთ ოფცია ‑no‑data‑checksums;
- pg_createsubscriber უტილიტაში დაემატა დროშა ‑all ლოგიკური რეპლიკების ერთი ბრძანებით ყველა DB-სთვის ერთდროულად შესაქმნელად;
- განხორციელდა პროტოკოლის ახალი ვერსია (3.2), რომელიც გამოიყენება გარე უტილიტების DBMS-თან ურთიერთქმედებისთვის და განხორციელებულია libpq ბიბლიოთეკაში. პროტოკოლის წინა განახლება განხორციელდა PostgreSQL 7.4-ში (2003 წელი). libpq ბიბლიოთეკაში ნაგულისხმევად კვლავ გამოიყენება ვერსია 3.0.